طريقة تشغيل هادوب بدوكر
البوست على تمبلر
صباح الخير ومساء الخير , في الكُلية الترم ده بندرس كورس Big data وعشان نشتغل بيج داتا لازم نستخدم hadoop.
وﻷن hadoop صعب في تسطيبه خصوصًا لحد مبيستخدمش لينكس كتير أنا قررت أساهم في تقليل مُعاناة الناس اللي أعرفهم وأشرح إزّاي نستخدمه جوّة docker.
Hadoop is hard to set up, use, and maintain. [*]
مش هشرح يعني إيه دوكر ﻷن ده موضوع تاني , لكن ببساطة دوكر هيوفّر التسطيب جاهز ع التشغيل على طول من غير تعب الـ installation والـ configuration اللي كُنّا هنعمله بإيدينا وده أكيد ﻷن حد تاني تعب وعمل الحاجات دي قبل كدة. كمان دوكر هيخلّي الموضوع أسهل إنّك تشيل hadoop تاني بسهولة برضو أو حتّى إنّك تشارك التعديلات بتاعتك مع الناس التانيين , ده في حالة لو كُنت إنت اللي بتشرح وعايز تشارك التعديلات بعد كُل خطوة.
المُهم , عشان نستخدم دوكر أكيد لازم نسطّبه , أنا هفترض إنّك بتستخدم أخر نُسخة من أوبنتو ﻷن أغلب اللي أعرفهم بيستخدم أخر نُسخة من أوبنتو.
عشان تسطّب دوكر هتكتب الأمر ده في الترمينال عشان:
sudo apt-get update
وبعدين تكتب باسوردك وبعدين تكتب الأمر ده:
sudo apt-get install docker.io
دلوقتي إنت عندك دوكر عشان تستخدمه هتقفل الأوّل الترمينال وبعدين تفتحها تاني وبعدين تكتب الأمر ده عشان تشوف التسطيب خلص بنجاح ولّا ﻷ:
sudo docker version
لو شغّال هيطبعلك كلام زي ده

بعد كدة هتكتب الأمر ده عشان تسطّب الـ image الخاصة بالهادوب:
sudo docker pull sequenceiq/hadoop-ubuntu:2.5.2
دلوقتي هو هيبدأ ينزّل hadoop بكُل الحاجات اللي هو محتاجها عشان يشتغل فالخطوة هتاخُد وقت على حسب النت بتاعك بس مُتوقّع إنّك تشوف حاجة شبه كدة طول ماهو شغّال بتبطّل لمّا التسطيب يخلص.
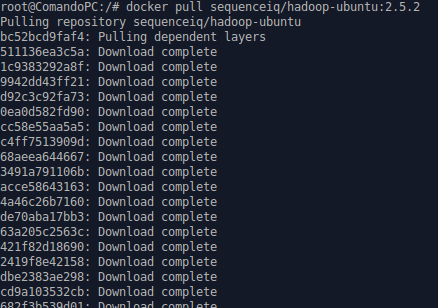
بعد ما يخلّص تحميل المفروض إنّك كدة خلّصت الخطوة اللي بتاخُد وقت بعد كدة هتدخُل عشان تستخدم بقى الإيمدج اللي نزلت , وده هيتم بالأمر ده:
sudo docker run -i -t sequenceiq/hadoop-ubuntu:2.5.2 /etc/bootstrap.sh -bash
هيقعد لوحده يعمل حاجات سيبه لحد ما يخلّص وهتلاقي حاجة شبه كدة :
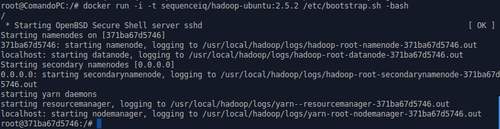
كدة التسطيب إنتهى وتقدر تستخدم hadoop من هنا , لكن عشان نتأكّد هنستخدم مثال من اللي بيبقى مع البرنامج , عن طريق الأوامر دي:
cd $HADOOP_PREFIX
وبعدين ده , بالمُناسبة الأمر ده إستخدم كُل الرام والبروسيسور اللي على الجهاز عندي:
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.2.jar grep input output ‘dfs[a-z.]+’
هياخُد وقت طويل في الأخر هتكتب ده:
bin/hdfs dfs -cat output/*
لو كُل حاجة خلصت زي الفُل هتشوف حاجة زي كدة:

طبعًا حاجات لازم أنوّه عنها , ملفّات جهازك مش accessible على دوكر , ﻷن دوكر بيعمل sandbox عشان يشغّل عليه الإيمدج بتاعتك.
كمان nano/emacs مش موجودين بشكل إفتراضي مع الإيمدج المُستخدمة في دوكر فهتحتاج تنزّل أيًا كان الإيديتور اللي بتحبّه بالطريقة العادية وليكُن:
sudo apt-get install nano
مع العلم إن vi موجود بس هو في حد أعرفه بيستخدم vi!
أخيرًا عشان تقفل دوكر هتكتب exit وبعدين إنتر عادي هيقفل وهيرجع للأوبيريتنج سيستم بتاعك تاني.
أخيرًا عشان تشغّله تاني هتكتب الأمر ده:
sudo docker ps -a
هيظهر حاجة زي كدة :

هناخُد الرقم الغريب اللي تحت CONTAINER ID ده وبعدين هنستخدمه عشان نشغّل الكونتينر أو نمسحه أو حتّى نعمل إيمدج منّه عشان نشغّل الكونتينر تاني هنستخدم الأمر ده
sudo docker start -i 0d6ce9027b25
عشان نمسحه هنستخدم ده
sudo docker rm 0d6ce9027b25
هتغير 0d6ce9027b25 وتستخدم اللي ظهر ليك ﻷنّه بيختلف من مرّة لمرّة.
مع ذلك ده بيمسح الكونتينر مش الإيمدج نفسها لو عايز تمسح الإيمدج نفسها هتستخدم الأمر ده
sudo docker rmi sequenceiq/hadoop-ubuntu
ودُمتم سالمين.